










MEASURING PERFORMANCE INDICATORS WITH ELK
Monitoring and measuring IT applications’ performance indicators are a major challenge for companies.
The evolution of technologies around qualification, storage and processing big data as well as machine learning has made it possible to improve monitoring in various areas (detection of fraud in financial transactions, system troubleshooting, facilitation of bug detection in Big Data applications…).
Monitoring relies heavily on logs. In general, these logs can be considered as structured or unstructured that and if exploited correctly can serve us in the detection of anomalies or incidents.
The log file is comprised of two parts::
- Timestamp: the date and time of the event.
- Data: Data that covers the operating system used, the server response, the system state, and possibly the error that occurred.
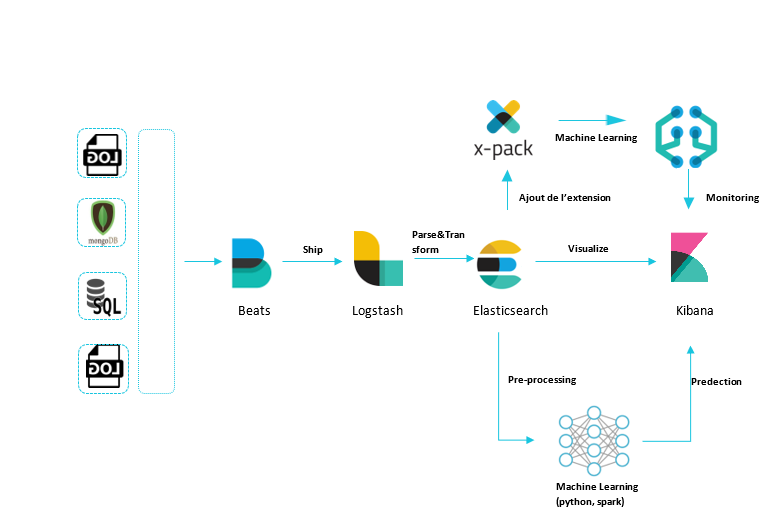
Today, we are going to talk about one of the possible monitoring methods, the use case of ELK (Elasticsearch, Logstash and Kibana) stack for data recovery, data centralization and data visualization. In a second step, we will discuss the use case of machine learning for the detection of anomalies in logs.
The processing of log data can be divided as the following:
- Extraction of data: from different databases
- Data Structuring: by using Log Analyzer (Logstash)
- Data Centralization: by using Elasticsearch
- Data Visualization: by using Kibana to understand the data and help see the anomalies.
- Learning data: using python for example. This treatment will be divided into 3 stages
i. Data cleaning
ii. Pre-processing
iii. Prediction
 The ELK stack is a tool used by major market players, known to handle large volumes of data like Facebook, Amazon and eBay.
The ELK stack is a tool used by major market players, known to handle large volumes of data like Facebook, Amazon and eBay.
The ELK stack is composed of three platforms; Elasticsearch, Logstash and Kibana that we will detail below.
ELASTICSEARCH: THE BATTERY HEART
Elasticsearch is a search engine based on Lucene. It has the ability to process terra-bytes or even peta-bytes of data by requesting in JSON format.
Elasticsearch can index heterogeneous data and centralize them according to mapping configurations. Communication with Elasticsearch is done via http: REST API request on port 9200.
Elasticsearch has several search features:
- Search lite: allows searching a given string in documents.
- QueryDSL search: allows you to use Lucene’s search functions via JSON.
It also relies on other analysis and search functions such as: bool, range, match, min, average.
Designed to handle large volumes of data, Elasticsearch is distributed by nature. It is horizontally scalable by adding nodes in a cluster. Thus, it works perfectly in a big data context.
LOGSTASH: THE PIPELINE
Open-source tool, it receives heterogeneous data parse and transform it to specified format.
Logstash has over 200 plugins that ease processing, regardless of source and format. The variety of filters makes logstash very powerful. It examines text or csv files, replaces sensitive data with a hash, analyzes an IP and adds position information, encodes a JSON field, renames delete and replaces fields.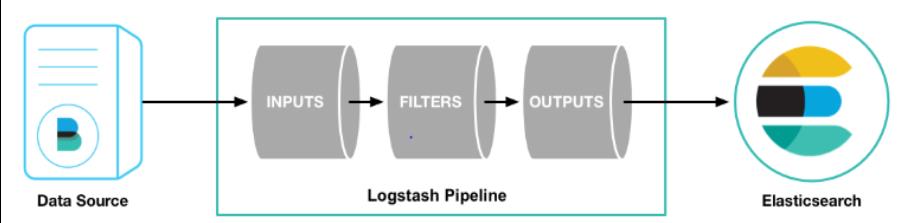
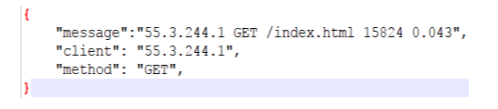
En entrée : 55.3.244.1 GET /index.html 15824 0.043
 Produit :
Produit :
 Logstash is equipped with several plugins that facilitate the data collection including Beats. It intervenes on the collecting part and transfers data from various sources. It is a lightweight framework found available in different versions:
Logstash is equipped with several plugins that facilitate the data collection including Beats. It intervenes on the collecting part and transfers data from various sources. It is a lightweight framework found available in different versions:
- FileBeat: transfer logs
- MetricBeat: transfer State data
- PacketBeat: transfer Network Status Data
- WinlogBeat: transfer Windows log
Note that Beats must be installed on servers that produce data.
KIBANA: THE VISUALIZATION OF THE RESULTS TOOL
Kibana is an open source platform whose role is to visualize results in the form of graphs, tables, maps and gauges. Rich web interface, it offers the possibility to create dashboards grouping the visuals mentioned.
It makes it easy to handle large volumes of data. It refines the interpretation of the results in real by descrinbing queries and transformations.
Note that the components presented in ELK stack are open source.
In addition to the components mentioned above, other paying extensions are offered by Elastic. In our article we will be looking at the X-pack extension.
X-PACK: THE MACHINE LEARNING EXTENSION
It offers bag of implemented algorithms and statistical methods to learn data flow models (training and modeling) in order to predict future behaviors, detect anomalies and visualize them in Kibana.

DATA PROCESSING AND PRECIDCTION ON DATA
We will begin by defining what an anomaly is and its characteristics, and then we will talk about approaches used in application monitoring.
An anomaly can be defined as an observed behavior which appears different to the expected or specified behavior. An anomaly is always caused by an error or a defect.
In the case of logs, the volume of data (up to thousands of lines per second) makes any manual approach very difficult. Moreover, the causes of anomalies and their occurrences remain unknown. It is therefore risky to try to label the data because we can forget certain types of anomalies. Their detection is similar to an unsupervised problem of machine learning (the data does not contain tags on the associated type of anomaly).
Being raw data, logs are difficult to enrich being fetched from different sources. In order to do this you must ensure that you have a unique identifier and / or the correct timestamp for all data you wish to cross.
There are numerous known methods for processing and enriching log data according to this case. Below will be presented some general approaches to log analysis:
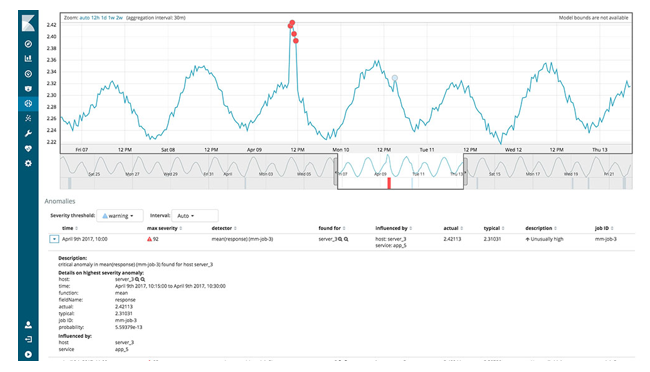
TIME SERIES
Based on numerical fields of a continuous space, Kibana allows you to easily and efficiently create beautiful time series graphs to facilitate its study.
Two detection methods are used; the first is to set a threhold at 3 times the standard deviation allowing the detecting of global anomalies in all time series. This threshold makes it possible to have a 99.7 %confidence rate of the data, which is situated between [- threhold , + threhold ]. However, this approach does not detect local anomalies as well as sudden changes in behavior.
Second method, more sophisticated than the previous one, analyzes the different fields separately and decomposes the seasonal series into seasonality and LOESS trend or STL (Seasonal and Trend decomposition using Loess). This method makes it possible to eliminate certain anomalies, which tend to repeat themselves.
These repetitive peaks are due to the seasonality of the time series and may not be actual anomalies. Following this decomposition, there is a statistical test that detects sudden changes that may be anomalies. This is the Generalized Extreme Studentized Deviate (G-ESD) test or ESD. (1)
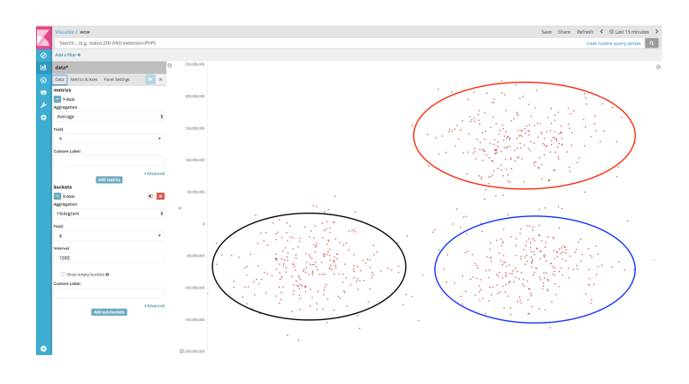
CLUSTERING
A more advanced pre-procession is needed to rely on this approach. It helps to only keep fields that seem most relevant in terms of information. Several clustering algorithms could be used. One of the most efficient in anomaly detection is DBSCAN. This algorithm does not require the fixing of a number of clusters, as they will form automatically.
DBSCAN requires 2 parameters:
- The minimum number of points within a geometric radius to form a cluster.
- The distance (epsilon) that specifies the required proximity between two points belonging to the same cluster. The optimal epsilon distance can be determined using the K algorithm (KNN) as presented in the article (2)
DEEP LEARNING
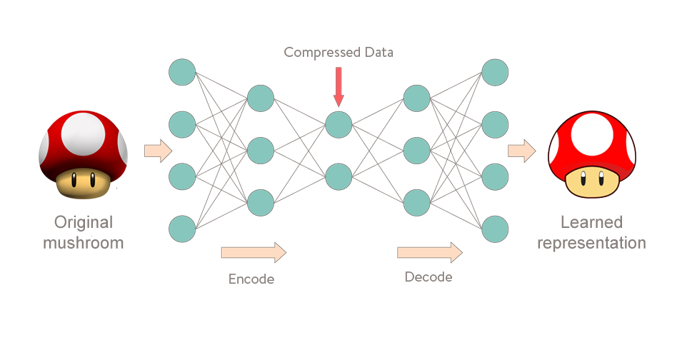
Neural networks (RN) have been proven to detect rare events such as anomalies. Today, thanks to technological evolution, it is possible to build networks of neurons bigger than ever.
Based on how the human brain functions, each neuron makes it possible to extract, combine or compress inputted information.
An example is the auto-encoder, which is a neural network that extracts useful information into the data, compresses it, and reconstructs it by learning the data’s normal behavior. This principle allows the algorithm to compare the inputted data and the reconstructed outputted data. If there is a significant difference between the two, it can detect normal behavior anomalies.
The steps for using the auto-encoder are the following:
- Train the model on data distribution considered “normal” (rare anomaly) via the principles of encoding and decoding.
- Minimization of the reconstruction error represented by the difference between input and output data (identity function).
- Try to reconstruct the test data based on the prediction of the model. If the error measured during the reconstruction is significant, it is an abnormal behavior and therefore an anomaly.
 To conclude, the ELK (Elasticsearch, Logstash and Kibana) stack is easily configurable and is suitable for monitoring and processing large volumes of data. Its X-pack extension based on machine learning provides an Advanced analysis of anomaly detection.
To conclude, the ELK (Elasticsearch, Logstash and Kibana) stack is easily configurable and is suitable for monitoring and processing large volumes of data. Its X-pack extension based on machine learning provides an Advanced analysis of anomaly detection.


