Qu’est-ce qu’un paradigme ?
C’est en effet une grande question : qu’est-ce qu’un paradigme de programmation ? Si on se base donc sur la définition du Larousse :
« Un paradigme est — en épistémologie et dans les sciences humaines et sociales – une représentation du monde, une manière de voir les choses, un modèle cohérent du monde qui repose sur un fondement défini (matrice disciplinaire, modèle théorique, courant de pensée). »
Alors appliqué à l’informatique cela nous donne cette définition du paradigme extraite de Wikipedia :
« Un paradigme de programmation fournit (et détermine) la vue qu’a le développeur de l’exécution de son programme. »
Un paradigme est donc une manière de programmer un ordinateur basé sur un ensemble de principes ou une théorie. Ce qui m’amène à cette phrase de Abraham Marslow : « Si le seul outil que vous avez est un marteau, vous verrez tout problème comme un clou. ». Que l’on pourrait traduire par : si un développeur ne comprend qu’un seul paradigme, il abordera toujours les problèmes de la même façon quitte à écrire un code inadapté ou inefficace.
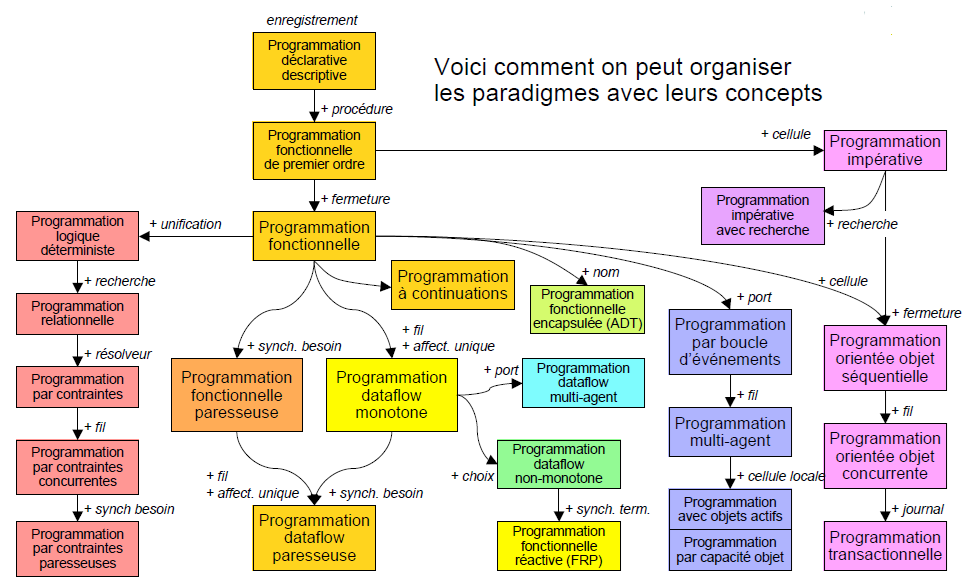
De fait, un paradigme de programmation est composé d’un ensemble de concepts. Et on crée un nouveau paradigme en partant d’un paradigme existant et en lui ajoutant un ou plusieurs nouveaux concepts. Voici donc une façon de les organiser proposée par P. Van Roy à la conférence UPMC :
Mais à quel paradigme de programmation se vouer ?
En somme, les paradigmes de programmation se sont démocratisés avec des langages phares qui les ont mis en avant. Certains ont eu plus de succès que d’autres… Voici néanmoins les paradigmes les plus utiles :
- Tout d’abord, l’architecture des processeurs depuis la seconde guerre mondiale jusqu’à aujourd’hui est intrinsèquement impérative… Les premiers langages implémentés (comme FORTRAN en 1954, ALGOL en 1958 ou COBOL en 1959) ont donc tout naturellement été basé sur le paradigme « impératif structuré ». C’est celui qui est le plus simple à comprendre pour la majorité des gens.
- Ensuite, les travaux de Church sur le λ-calcul et les travaux sur la calculabilité vont faire émerger le paradigme fonctionnel. Le premier langage populaire à l’implémenter fut LISP en 1958. Mais d’autres comme Haskell en 1990 ou Scala en 2003 en sont d’autres exemples.
- Par ailleurs, le paradigme de la programmation orienté objet (ou POO) a été inventé au début des années 1960 par les Norvégiens Ole-Johan Dahl et Kristen Nygaard et poursuivi par les travaux de l’Américain Alan Kay dans les années 1970. Ce sont les langages comme Simula 67 ou Smalltalk 71 qui l’ont popularisé. Aujourd’hui la plupart des langages supportent ce paradigme.
- De plus, le paradigme logique est né de travaux effectués de 1930 jusqu’en 1965 sur la démonstration automatique de théorème. C’est le langage PROLOG créé par Alain Colmerauer et Philippe Roussel (cocorico) vers 1972 à Luminy qui l’a popularisé.
- Enfin, le modèle par acteur est utilisé pour formaliser les interactions concurrentes. De fait les acteurs communiquent par échange de messages. En réponse à un message, un acteur peut effectuer un traitement local, créer d’autres acteurs, ou envoyer d’autres messages. L’article de référence date de 1973. Le langage qui l’implémente le plus connu est Erlang. Il est en effet très utile dans le monde de l’embarqué.
Aujourd’hui la plupart des langages sont multi-paradigmes.
Python, Java, C++ et C# supportent le paradigme impératif structuré, fonctionnel et objet, par exemple. En fonction du problème à résoudre, il sera plus intéressant de travailler avec un paradigme plutôt qu’un autre :
- En effet, un calcul matriciel se gère plus facilement avec de l’impératif structuré
- De plus, un parcours d’arbre ne peut s’effectuer simplement qu’avec de la programmation fonctionnelle
- Enfin, les interfaces graphiques évoluées font un usage de la POO.
Quelques concepts de paradigme…
Un paradigme est composé d’un ensemble concepts. Nous allons donc lister les plus important d’entre eux.
Concept de paradigme : enregistrement
Effectivement, un enregistrement est un regroupement de données avec un accès direct à chaque donnée. C’est le type RECORD du langage Pascal ou le struct du C.
p=Personne( prenom=’Jean’, nom=’De Bon Fumet’, telephone=’0102030405’ )
p.nom est égal à “De Bon Fumet”
Les enregistrements doivent proposer un certain nombre d’opérations : création, décomposition, les examiner, de manière dynamique pendant l’exécution. Afin de construire les types complexes comme les listes, les chaînes et les arbres, ils seront dérivés des enregistrements. Les enregistrements sont un point de départ nécessaire pour bâtir d’autres techniques comme la programmation orientée objet. Programmation orientée objet qui sert à construire les interfaces graphiques et la programmation par composants.
Concept de paradigme : fermeture ou clôture
C’est en effet une des bases du paradigme de programmation fonctionnel. Le terme complet est « fermeture à portée lexicale » (en anglais : lexically scoped closure) ou clôture (en anglais : closure). D’un point de vue pratique, une fermeture regroupe une procédure avec ses références externes. Une fermeture est donc créée, entre autres, lorsqu’une fonction est définie dans le corps d’une autre fonction et fait référence à des arguments ou des variables locales à la fonction dans laquelle elle est définie. Voici un petit exemple en python :
def new_adder( increment ):
def add( x ):
return x + increment
return add
add5 = new_adder( 5 )
add15 = new_adder( 15 )
print( "add5=", add5( 10 ) )
print( "add15=", add15( 10 ) )
Les fermetures sont partout : les fonctions et les objets sont des fermetures.
Concept de paradigme : l’indépendance
C’est un concept clé car il induit comment créer un programme en parties indépendantes. Il est la base de plusieurs concepts dérivés :
- La concurrence : les activités concurrentes s’exécutent en même temps sans interactions
- Le choix non-déterministe : interactions indirectes entre les activités
- L’état : interactions directes entre les activités
L’indépendance : la concurrence
Le monde réel est, par essence, concurrent : vous et moi évoluons et vivons de manière totalement indépendante et concurrente… De même l’informatique est concurrent :
- Sur un réseau chaque ordinateur agit de manière concurrente : c’est un système distribué
- Sur un système d’exploitation de nombreux programmes/services (représentés par des processus) agissent de façon concurrente. Chaque processus a une mémoire indépendante.
- A l’intérieur d’un processus, plusieurs fils d’exécution (threads) peuvent coexister. Les fils partagent la même mémoire.
Pour qu’un programme concurrent puisse fonctionner, il faut que les différentes activités puissent communiquer (échanger des informations) et se synchroniser (attendre qu’un événement survienne pour poursuivre l’activité). Il y a différents types de concurrence qui forment 4 sous-concepts.
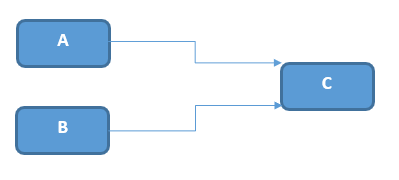
L’indépendance : le choix non-déterministe
Nous avons trois entités (A, B et C). A et B peuvent interagir avec C mais A et B n’ont pas d’influence l’une sur l’autre. C reçoit des messages de A et de B indépendamment et, donc, fait un choix.
L’indépendance : l’état
Concernant le paradigme de programmation, il y a principalement deux formes d’état. D’abord, le premier est la variable affectable que l’on retrouve dans la majorité des langages (comme C, C++, Java, C# ou Python) … D’autre part, la seconde est le canal de communication comme dans le langage Erlang.
Le canal de communication permet la concurrence par envoi de messages (systèmes distribués par exemple) et les variables permettent la concurrence par mémoire partagée.
Le principal défaut de l’état c’est que l’état d’une partie du programme peut devenir erroné et cela est difficile à détecter et corriger : par exemple, le crash pour Access Violation ou SIGSEGV en C++.
Concept de paradigme : abstraction de données
Dans le paradigme de programmation, C’est une manière d’organiser l’utilisation des données selon des règles. De fait, il y a 3 types : l’encapsulation, le polymorphisme et l’héritage.
Abstraction de données : l’encapsulation
Dans le paradigme de programmation, en ce qui concerne l’encapsulation, c’est une boîte noire avec un intérieur et une interface pour interagir avec l’extérieur. L’encapsulation a différents avantages :
- Si l’interface est bien définie alors l’abstraction fonctionnera toujours
- Elle réduit la complexité car l’utilisateur n’a pas besoin de comprendre comment l’abstraction est réalisée
- Par ailleurs, les abstractions permettent d’écrire de plus gros programmes en diminuant les risques. En effet, comme l’on travaille à travers des interfaces, il est plus facile de modifier les implémentations derrière une encapsulation sans avoir à réécrire le code qui l’utilise
Par conséquent, les objets sont un exemple de cette encapsulation.
Abstraction de données : le polymorphisme
Dans le paradigme de programmation, une entité est alors dite polymorphe si elle peut prendre différentes formes. Cela sera donc facilité avec les objets.
Une opération est de fait polymorphe si elle peut prendre des arguments différents. On peut prendre comme exemple l’opération ‘+’ qui s’applique aux entiers, aux nombres flottants, aux chaînes de caractères et même les listes…
Abstraction de données : l’héritage
Dans le paradigme de programmation, l’héritage est alors une conséquence que la ‘fainéantise’ du développeur (tout sportif intelligent évite l’effort inutile) : pour créer de nouvelles abstractions en se basant sur d’autres abstractions, on souhaite le faire sans réécrire le code commun ; et donc éviter le code dupliqué qui est une source de risques. L’héritage apporte donc son lot de difficultés comme l’héritage en diamant raison pour laquelle C# et Java interdisent l’héritage multiple.
Envie d’en savoir plus sur l’encapsulation, le polymorphisme et l’héritage ? Découvrez notre article à ce sujet de Mamadou SECK.